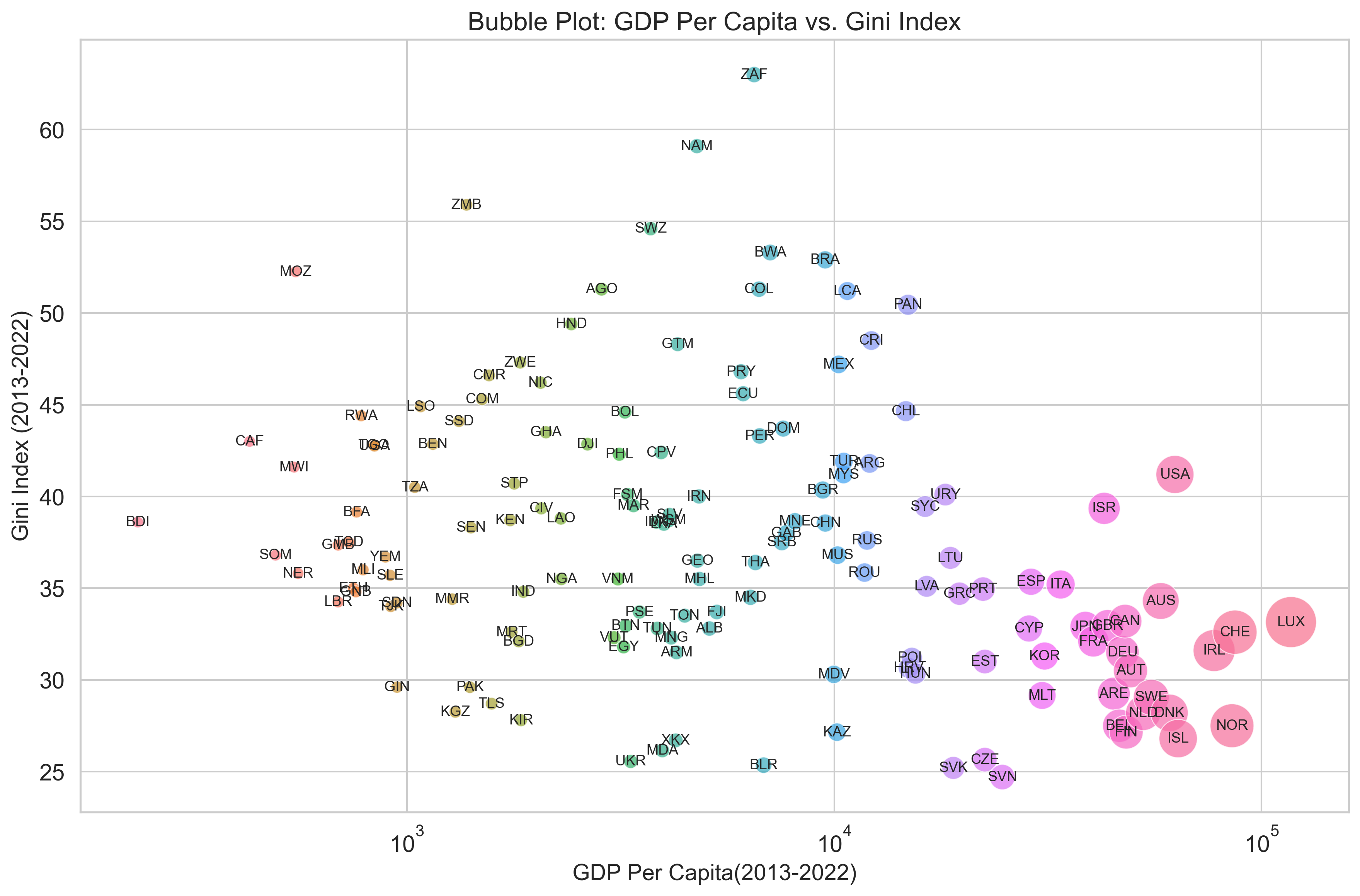
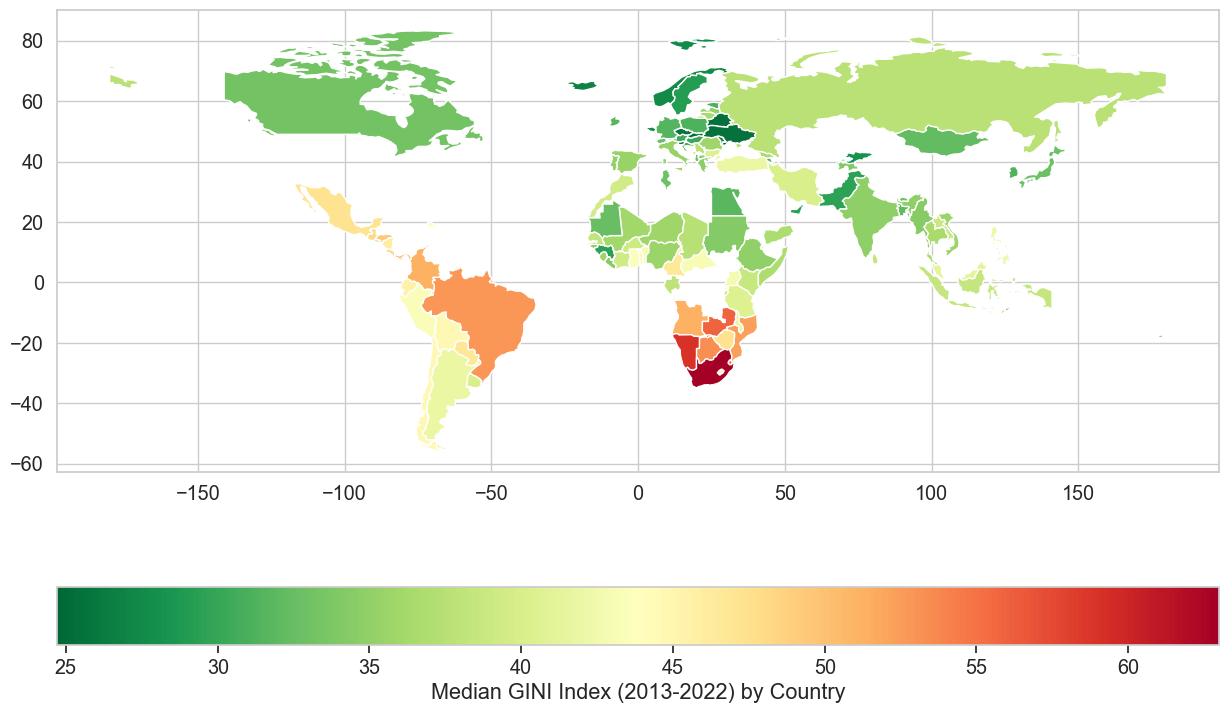
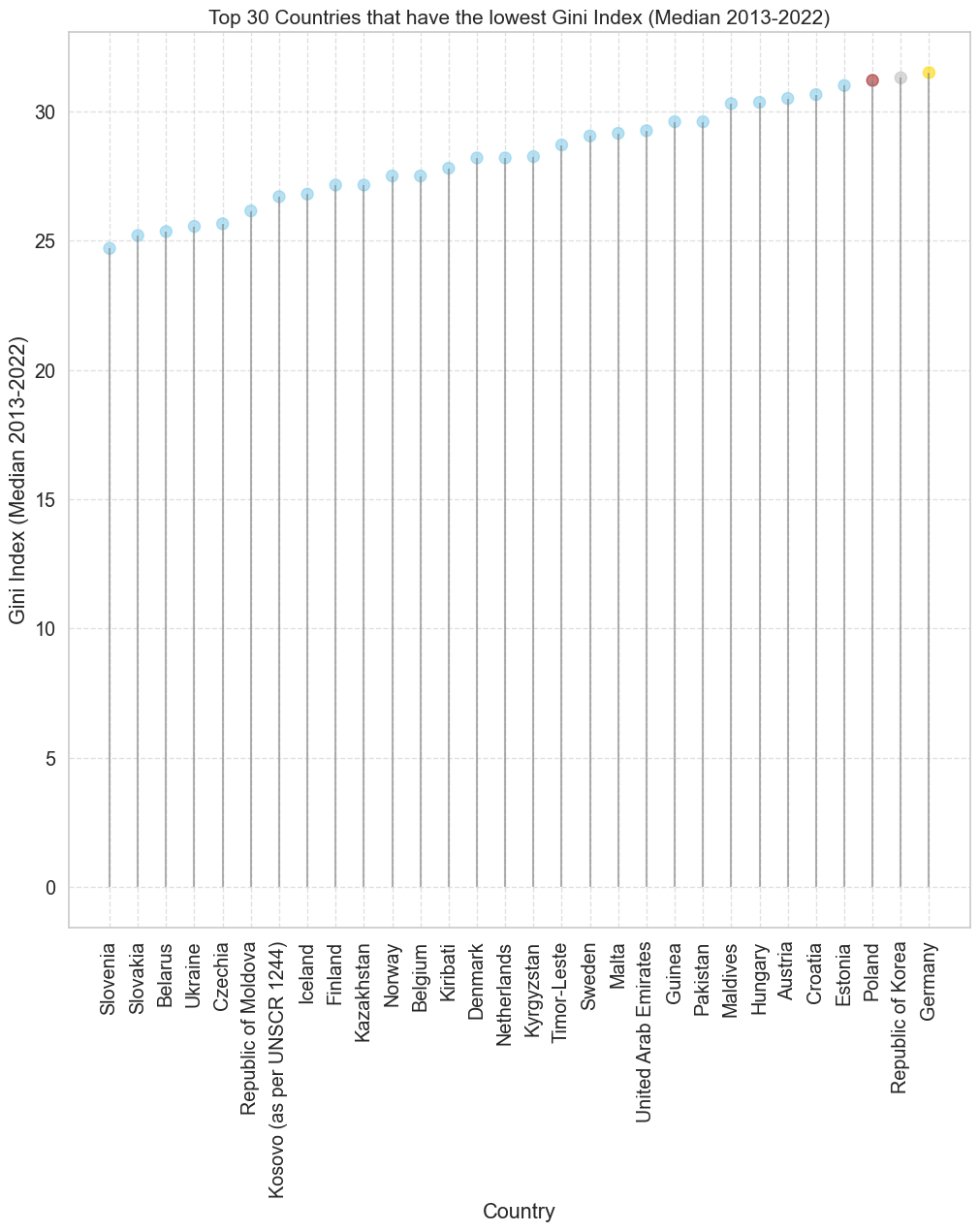
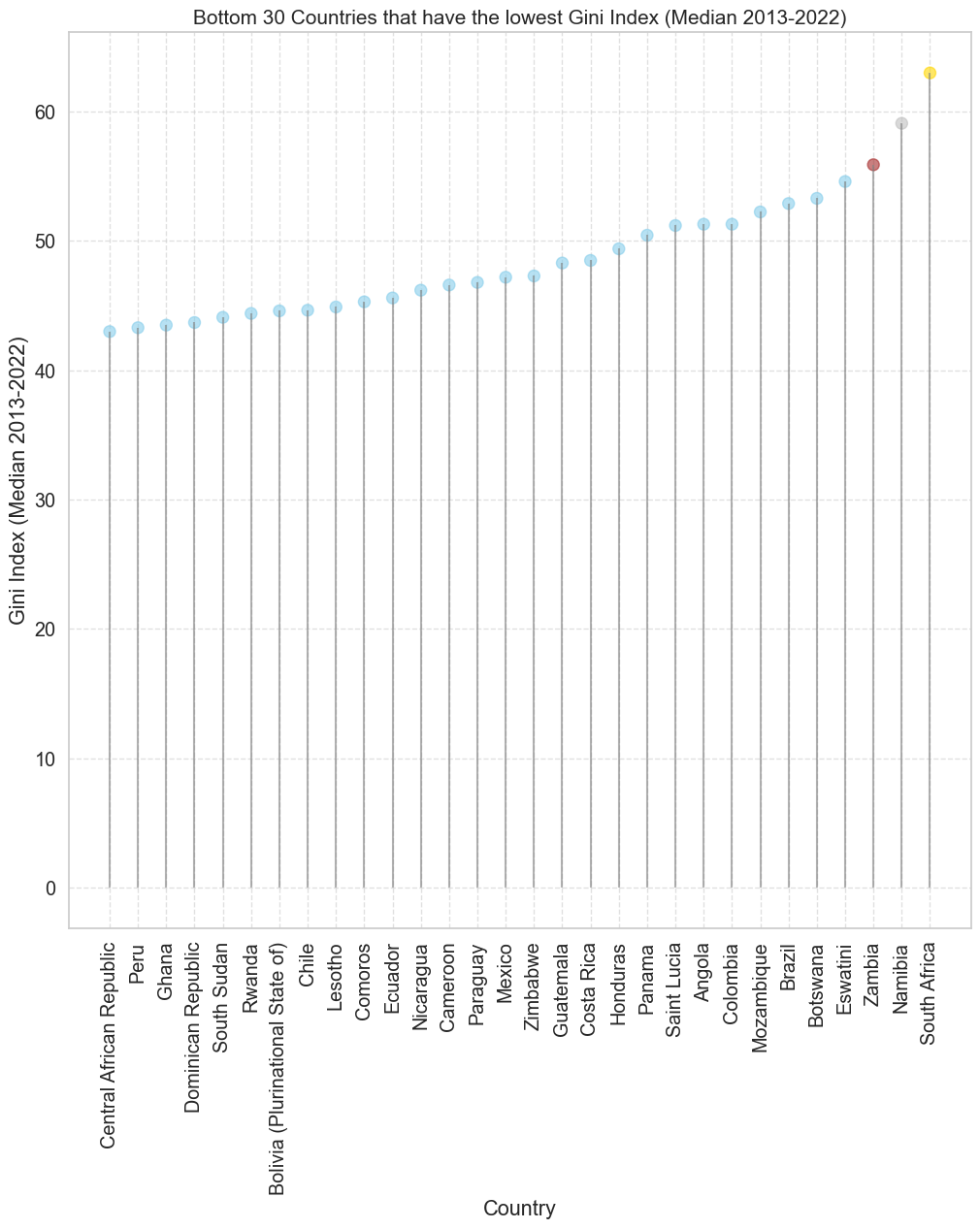
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
# Define file paths
gini_file_path = r"C:\Users\11\Desktop\Python\Python Project\Global Inequlity Analysis\Gini Index.xlsx"
gdp_file_path = r"C:\Users\11\Desktop\Python\Python Project\Global Inequlity Analysis\NationalGDP.xls"
# Read the Excel files
df = pd.read_excel(gini_file_path, engine="openpyxl")
GDP = pd.read_excel(gdp_file_path, engine="xlrd")
# Clean column names by stripping spaces and replacing inner spaces with underscores
GDP.columns = GDP.columns.str.strip().str.replace(r'\s+', '_', regex=True)
df.columns = df.columns.str.strip().str.replace(r'\s+', '_', regex=True)
# Pivot the Gini Index table so that each country's yearly values become columns
pivot_df = df.pivot_table(values="Gini_Index", index=['Country', 'ISO-3_Code'], columns="Year")
# Select the years 2013 to 2022
IEQ_10 = pivot_df[[2013, 2014, 2015, 2016, 2017, 2018, 2019, 2020, 2021, 2022]]
GDP_10 = GDP[['Country_Code', '2013', '2014', '2015', '2016', '2017', '2018', '2019', '2020', '2021', '2022']]
# Compute the median Gini Index (IEQ value) for each country
IEQ_10_Median = IEQ_10.median(axis=1).reset_index()
# Compute the mean GDP across the selected years for each country
GDP_10_Mean = GDP_10.set_index('Country_Code').mean(axis=1).reset_index()
# Rename ISO-3_Code to Country_Code in the IEQ dataframe for merging
IEQ_10_Median.rename(columns={"ISO-3_Code": "Country_Code"}, inplace=True)
# Merge the two datasets on Country_Code
Co_IEQ_GDP = IEQ_10_Median.merge(GDP_10_Mean, on='Country_Code', suffixes=('_ieq', '_gdp'))
# For clarity, rename the merged numeric columns to '0_ieq' and '0_gdp'
# The merged DataFrame typically ends up with the new GDP column as the third column.
Co_IEQ_GDP.rename(columns={Co_IEQ_GDP.columns[2]: '0_ieq', Co_IEQ_GDP.columns[3]: '0_gdp'}, inplace=True)
print(Co_IEQ_GDP.head())
# Drop rows with non-finite values in '0_gdp' or '0_ieq'
Co_IEQ_GDP = Co_IEQ_GDP[np.isfinite(Co_IEQ_GDP['0_gdp']) & np.isfinite(Co_IEQ_GDP['0_ieq'])]
# Sort the DataFrame by '0_gdp' (mean GDP) in ascending order
Co_IEQ_GDP = Co_IEQ_GDP.sort_values(by='0_gdp', ascending=True)
# Set up the bubble plot figure
plt.figure(figsize=(12, 8))
sns.set_theme(style="whitegrid", palette="muted", font="sans-serif", font_scale=1.3)
plt.figure(figsize=(12, 8), dpi=300)
# Create the bubble plot:
scatter = sns.scatterplot(
data=Co_IEQ_GDP,
x='0_gdp', # x-axis: mean GDP
y='0_ieq', # y-axis: median Gini Index
size='0_gdp', # Bubble size based on mean GDP (you can change this if desired)
sizes=(50, 1000), # Adjust bubble size range
alpha=0.7, # Transparency for bubbles
hue='Country',
legend=False,
)
# Annotate each bubble with the Country_Code
for _, row in Co_IEQ_GDP.iterrows():
# Only annotate if both values are finite
if np.isfinite(row['0_gdp']) and np.isfinite(row['0_ieq']):
plt.text(row['0_gdp'], row['0_ieq'], row['Country_Code'],
fontsize=9, ha='center', va='center')
plt.xscale('log')
# Customize the plot
plt.title("Bubble Plot: GDP Per Capita vs. Gini Index", fontsize=16)
plt.xlabel("GDP Per Capita(2013-2022)", fontsize=14)
plt.ylabel("Gini Index (2013-2022)", fontsize=14)
plt.grid(True)
plt.tight_layout()
# Display the plot
plt.show()